
|
|
About MeI am a Senior Research Scientist in the Creative Vision Team at Snap Inc. I and my team work on a variety of projects related to understanding, capturing, manipulating, and rendering the world from images, as well as other topics related to cross-modal media synthesis and efficient neural network architectures.I was previously a Ph.D. student at the University of Southern California, working in the Geometric Capture Lab under Hao Li, where I worked on various projects, including facial expression for emerging platforms such as VR/AR headsets, 3D reconstruction from 2D images, and intuitive interfaces for image manipulation and synthesis. My research has been published in venues such as SIGGRAPH, SIGGRAPH Asia, ICCV and CVPR. I was a recipient of the 2018 Snap Research Fellowship. |
Selected Press
[12/26/2022] AiThority: "Snap Researchers Introduce NeROIC for Object Capture and Rendering Applications. AiT Staff.[12/25/2022] Marktechpost: "Meet NeROIC: An Efficient Artificial Intelligence (AI) Framework For Object Acquisition Of Images In The Wild. Daniele Lorenzi.
[08/09/2022] Auganix Augmented Reality News: "Snap Presents New "NeROIC" Research Paper at SIGGRAPH on Digital Asset Creation from Multiple Images. Sam Sprigg.
[08/08/2022] Snap Newsroom: "Snap Research Creates a New Way to Digitize and Render Assets for Augmented Reality."
[08/08/2022] Snap AR: "NeROIC Research Paper at SIGGRAPH 2022" (YouTube).
[02/12/2022] What's AI: "Create Realistic 3D Models with AI!" (YouTube), Louis Bouchard. Blog post.
[08/31/2020] Shoot: "SIGGRAPH Bestows CG Awards, Wraps Its 1st Virtual Confab."
[08/28/2020] FX Guide: "Real-Time Live Winner: Monoport." Mike Seymour.
[08/26/2020] ACM SIGGRAPH Blog: "Broadcast From Around the World: Real-Time Live! Amazes at SIGGRAPH 2020.
[11/19/2019] Radiolab: "Breaking News." (Podcast) Simon Adler.
[10/24/2017] Wired: "How Digital Avatars Could Be the Future of Fake News" (YouTube).
[10/11/2016] USC News: "Who wants to show up as Gandalf at their next meeting?" Daniel Druhora.
[05/21/2015] Wired: "Oculus can map your real-life expressions onto your VR avatar." Katie Collins.
[05/21/2015] Engadget: "Oculus VR figures out how avatars can mimic your facial expressions." Mariella Moon.
[05/20/2015] MIT Technology Review: "Oculus Rift Hack Transfers Your Facial Expressions onto Your Avatar." Tom Simonite.
[10/23/2015] Voices of VR: "Oculus Research Collaborator Talks Tracking Facial Expressions While Wearing a VR Headset. (Podcast)." Kent Bye.
Exhibition

|
Volumetric Human Teleportation
Ruilong Li, Kyle Olszewski, Yuliang Xiu, Shunsuke Saito, Zeng Huang, Hao Li SIGGRAPH Real-Time Live 2020 (Winner, Best in Show Award) Project Paper arXiv YouTube Bibtex |
Publications

|
3D VADER: AutoDecoding Latent 3D Diffusion Models
Evangelos Ntavelis, Aliaksandr Siarohin, Kyle Olszewski, Chaoyang Wang, Luc Van Gool, Sergey Tulyakov Neural Information Processing Systems (NeurIPS 2023) Project Paper arXiv Bibtex |

|
Unsupervised Volumetric Animation
Aliaksandr Siarohin, Willi Menapace, Ivan Skorokhodov, Kyle Olszewski, Hsin-Ying Lee, Jian Ren, Menglei Chai, Sergey Tulyakov Computer Vision and Pattern Recognition (CVPR 2023) Project Paper arXiv Code Bibtex |

|
Control-NeRF: Editable Feature Volumes for Scene Rendering and Manipulation
Verica Lazova, Vladimir Guzov, Kyle Olszewski, Sergey Tulyakov, Gerard Pons-Moll Winter Conference on Applications of Computer Vision 2023 (WACV 2023) Project Paper arXiv Video Bibtex |

|
ScanEnts3D: Exploiting Phrase-to-3D-Object Correspondences for Improved Visio-Linguistic Models in 3D Scenes
Ahmed Abdelreheem, Kyle Olszewski, Hsin-Ying Lee, Peter Wonka, Panos Achlioptas Winter Conference on Applications of Computer Vision 2024 (WACV 2024) Project arXiv Bibtex |
|
Discrete Contrastive Diffusion for Cross-Modal Music and Image Generation
Ye Zhu, Yu Wu, Kyle Olszewski, Jian Ren, Sergey Tulyakov, Yan Yan International Conference on Learning Representations (ICLR 2023) Project Paper arXiv Code Supp Bibtex |

|
Cross-Modal 3D Shape Generation And Manipulation
Zezhou Cheng, Menglei Chai, Jian Ren, Hsin-Ying Lee, Kyle Olszewski, Zeng Huang, Subhransu Maji, Sergey Tulyakov European Conference on Computer Vision (ECCV 2022) Project Paper arXiv Code Bibtex |

|
R2L: Distilling Neural Radiance Field to Neural Light Field for Efficient Novel View Synthesis
Huan Wang, Jian Ren, Zeng Huang, Kyle Olszewski, Menglei Chai, Yun Fu, Sergey Tulyakov European Conference on Computer Vision (ECCV 2022) Project Paper arXiv Code Bibtex |
|
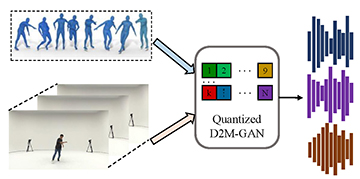
Quantized GAN for Complex Music Generation from Dance Videos
Ye Zhu, Kyle Olszewski, Yu Wu, Panos Achlioptas, Menglei Chai, Yan Yan, Sergey Tulyakov European Conference on Computer Vision (ECCV 2022) Project Paper arXiv Code Bibtex |

|
NeROIC: Neural Rendering of Objects from Online Image Collections
Zhengfei Kuang, Kyle Olszewski, Menglei Chai, Zeng Huang, Panos Achlioptas, Sergey Tulyakov ACM Transactions on Graphics (SIGGRAPH 2022) Project Paper arXiv YouTube Code Bibtex |

|
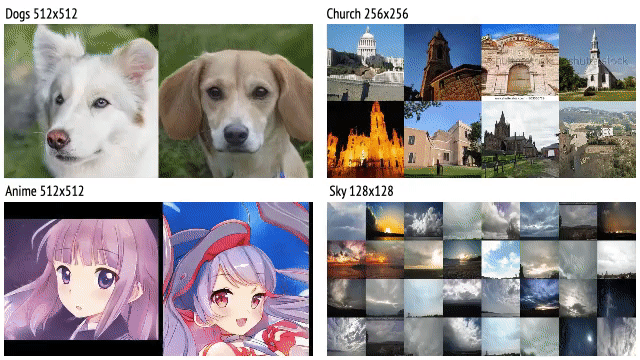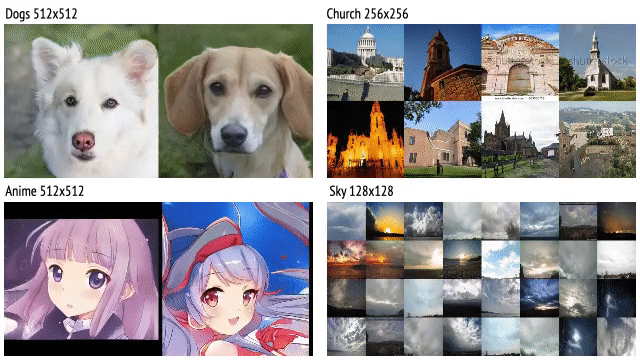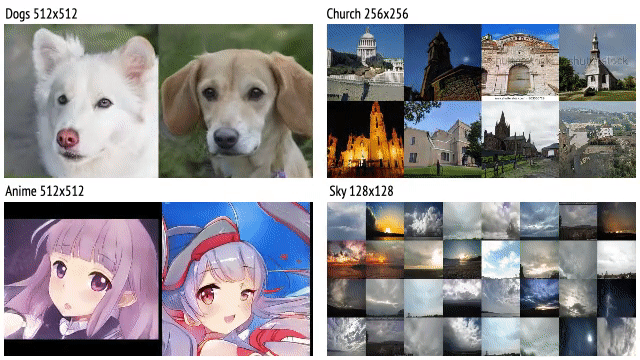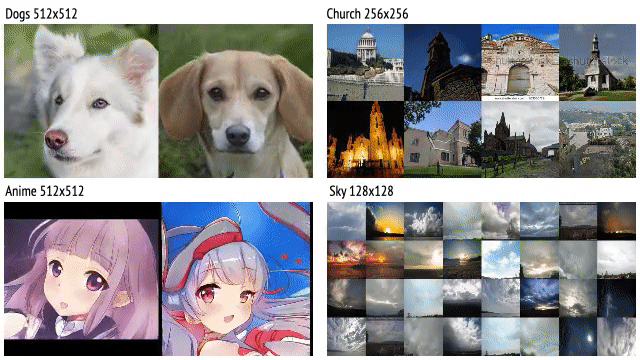
Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
Ligong Han, Jian Ren, Hsin-Ying Lee, Francesco Barbieri, Kyle Olszewski, Shervin Minaee, Dmitris Metaxas, Sergey Tulyakov Computer Vision and Pattern Recognition (CVPR 2022) Project Paper arXiv Code Dataset Bibtex |
|
A Good Image Generator Is What You Need for High-Resolution Video Synthesis
Yu Tian, Jian Ren, Menglei Chai, Kyle Olszewski, Xi Peng, Dmitris Metaxas, Sergey Tulyakov International Conference on Learning Representations (ICLR 2021) Project Paper arXiv slides presentation Code Supp Bibtex |

|
Flow Guided Transformable Bottleneck Networks for Motion Retargeting
Jian Ren, Menglei Chai, Oliver Woodford, Kyle Olszewski, Sergey Tulyakov Computer Vision and Pattern Recognition (CVPR 2021) Project Paper arXiv Supp bibtex Bibtex |

|
Intuitive, Interactive Beard and Hair Synthesis with Generative Models
Kyle Olszewski, Duygu Ceylan, Jun Xing, Jose Echevarria, Zhili Chen, Weikai Chen, Hao Li Computer Vision and Pattern Recognition (CVPR 2020, Oral Presentation) Project Paper arXiv YouTube Video Supp Bibtex |

|
Monocular Real-Time Volumetric Performance Capture
Ruilong Li*, Yuliang Xiu*, Shunsuke Saito, Zeng Huang, Kyle Olszewski, Hao Li European Conference on Computer Vision (ECCV 2020) Project Paper arXiv YouTube Bibtex |

|
Transformable Bottleneck Networks
Kyle Olszewski, Sergey Tulyakov, Oliver Woodford, Hao Li, Linjie Luo International Conference on Computer Vision 2019 (ICCV 2019, Oral Presentation) Project Paper arXiv YouTube Video Code Supp Bibtex |
|
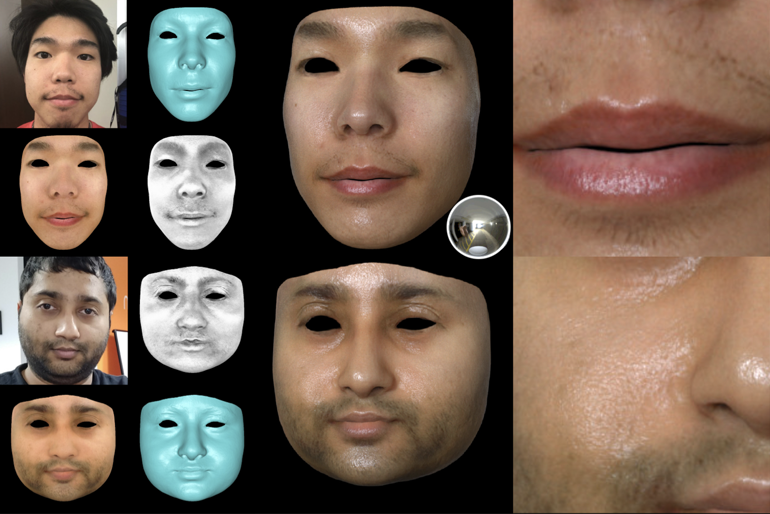
High-Quality Facial Reflectance and Geometry Inference from an Unconstrained Image
Shugo Yamaguchi, Shunsuke Saito, Koki Nagano, Yajie Zhao, Weikai Chen, Kyle Olszewski, Shigeo Morishima, Hao Li ACM Transactions on Graphics (SIGGRAPH 2018) Paper YouTube Video Supp Bibtex |
|
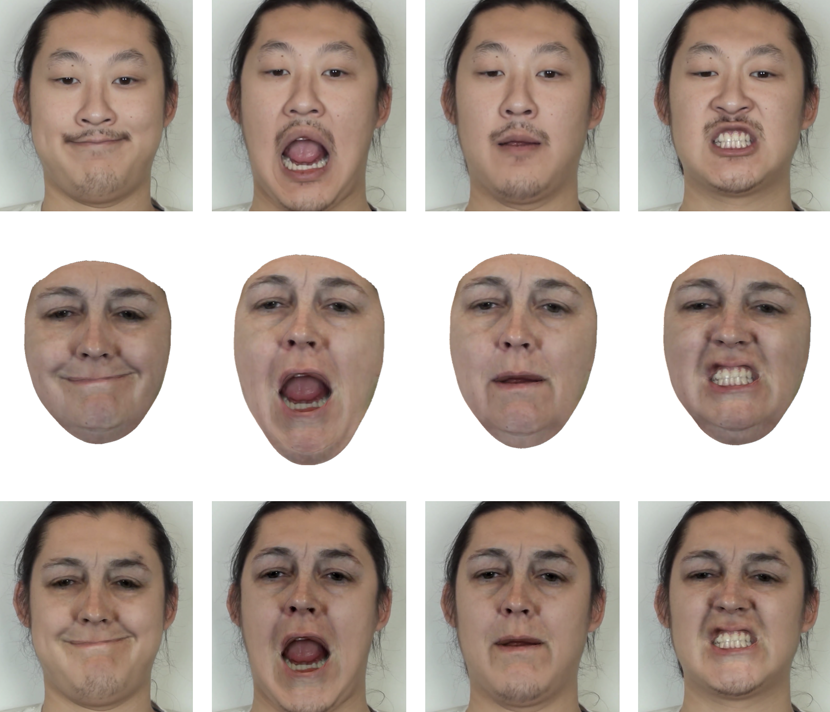
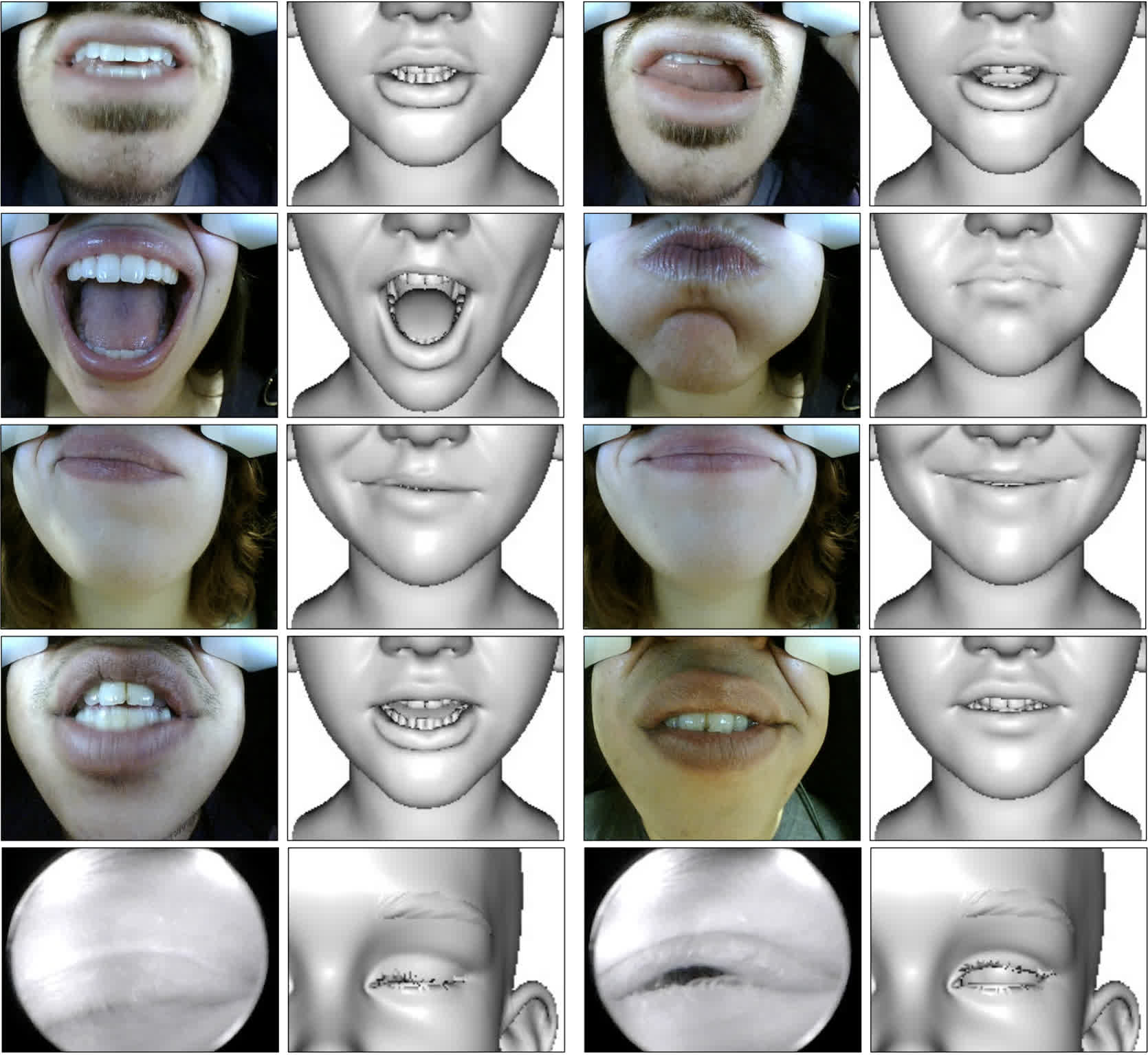
Realistic Dynamic Facial Textures from a Single Image using GANs
Kyle Olszewski*, Zimo Li*, Chao Yang*, Yi Zhou, Ronald Yu, Zeng Huang, Sitao Xiang, Shunsuke Saito, Pushmeet Kohli, Hao Li International Conference on Computer Vision (ICCV 2017) Paper YouTube Video Supp Bibtex |
|
High-Fidelity Facial and Speech Animation for VR HMDs
Kyle Olszewski, Joseph Lim, Shunsuke Saito, Hao Li ACM SIGGRAPH Conference and Exhibition in Asia (SIGGRAPH Asia 2016) Paper YouTube Video Bibtex |

|
Rapid Photorealistic Blendshape Modeling from RGB-D Sensors
Dan Casas, Andrew Feng, Oleg Alexander, Graham Fyffe, Paul Debevec, Ryosuke Ichikari, Hao Li, Kyle Olszewski, Evan Suma, Ari Shapiro Computer Animation and Social Agents (CASA 2016) Paper Video Bibtex |

|
Facial Performance Sensing Head-Mounted Display
Hao Li*, Laura Trutoiu*, Kyle Olszewski*, Lingyu Wei*, Tristan Trutna, Pei-Lun Hsieh, Aaron Nicholls, Chongyang Ma ACM Transactions on Graphics (SIGGRAPH 2015) Paper YouTube Video Bibtex |
© 2023 Kyle Olszewski