Transformable Bottleneck Networks
Kyle Olszewski, Sergey Tulyakov, Oliver Woodford, Hao Li, and Linjie Luo
University of Southern California Snap Inc.
USC Institute for Creative Technologies
Abstract
Spotlight video
Architecture
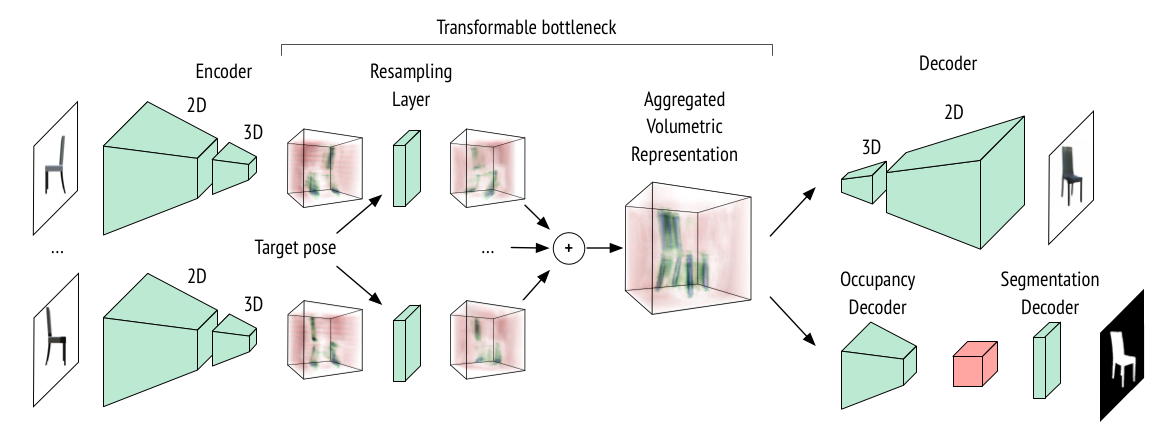
The TBN architecture consists of three parts: 2D-3D encoder followed by a resampling layer, and a 3D-2D decoder network. The resampling layer transforms an encoded bottleneck to the target view via trilinear interpolation. During training TBNs use 2D supervision only, including RGB images and foreground masks.
Novel View Synthesis

TBNs can be efficiently trained on a variety of diverse objects. We show TBN generated novel views of chairs, cars, and humans. We note that TBNs can generate intermediate views of objects not seen during training. To perform novel view synthesis we simply rotate the transformable bottleneck and decode it.
3D Reconstruction
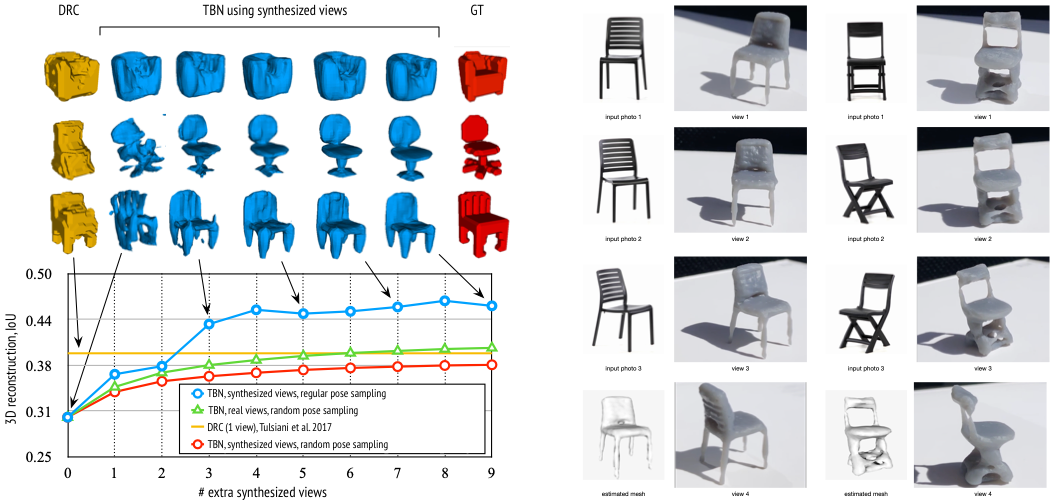
We trained a simple occupancy decoder applied on the transformable bottleneck. No 3D information was used during training, TBNs learn to reconstruct 3D structure of objects in the bottleneck using only 2D supervision. We then extract 3D meshes of objects represented using in the bottleneck. Given only a single input image a TBN can generate arbitrary number of novel views of this object and reuse them refining the predicted 3D shapes. We then use images of real objects to reconstruct their 3D shape and 3D print the predicted meshes.
Creative and Interactive Manipulations

We apply various manipulations directly on the transformable bottlenecks and decode them to obtain images. We note that the manipulations applied on the bottleneck translate to the same manipulations in the image space. TBNs can then render such manipulated object under various novel views. We show vertical twisting, where the bottom part of the chair is rotated to the direction opposite to the top part of the chair. Horisontal stitching, where the seat of the chair is moved up and down making a regular chair look like a bar stool. Nonlinear inflation, where all the parts of chairs are inflated and deflated. We note that under all these creative manipulations the objects still look realistic.

We use our approach to interactively rotate and deform objects inferred from real images before composing them into a target image. Given the 2 real images seen below and their estimated relative poses, a single aggregated bottleneck is computed. An interactive interface then allows the user to rotate, translate, scale and stretch the objects, thus transforming and rendering the bottleneck in real-time.


Citation
@article{olszewski2019tbn,
title={Transformable Bottleneck Networks},
author={Olszewski, Kyle and Tulyakov, Sergey and Woodford, Oliver and Li, Hao and Luo, Linjie},
journal={The IEEE International Conference on Computer Vision (ICCV)},
month={Nov},
year={2019}
}